# Save for use in subsequent chapterssaveRDS(panel, "sim_data.rds")write.csv(panel[, c("id", "year", "y", "first_treat", "treated")],"sim_data.csv", row.names =FALSE)
3.3 True Treatment Effects
Let’s calculate and display the true treatment effects for validation:
library(dplyr)
Attaching package: 'dplyr'
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
# Calculate true ATT by cohort and event timetrue_effects <- panel %>%filter(treated) %>%mutate(event_time = year - g) %>%group_by(g, event_time) %>%summarise(true_att =mean(tau_gt),n_obs =n(),.groups ="drop" )# Overall ATToverall_att <-mean(panel$tau_gt[panel$treated])cat("Overall true ATT:", round(overall_att, 4), "\n\n")
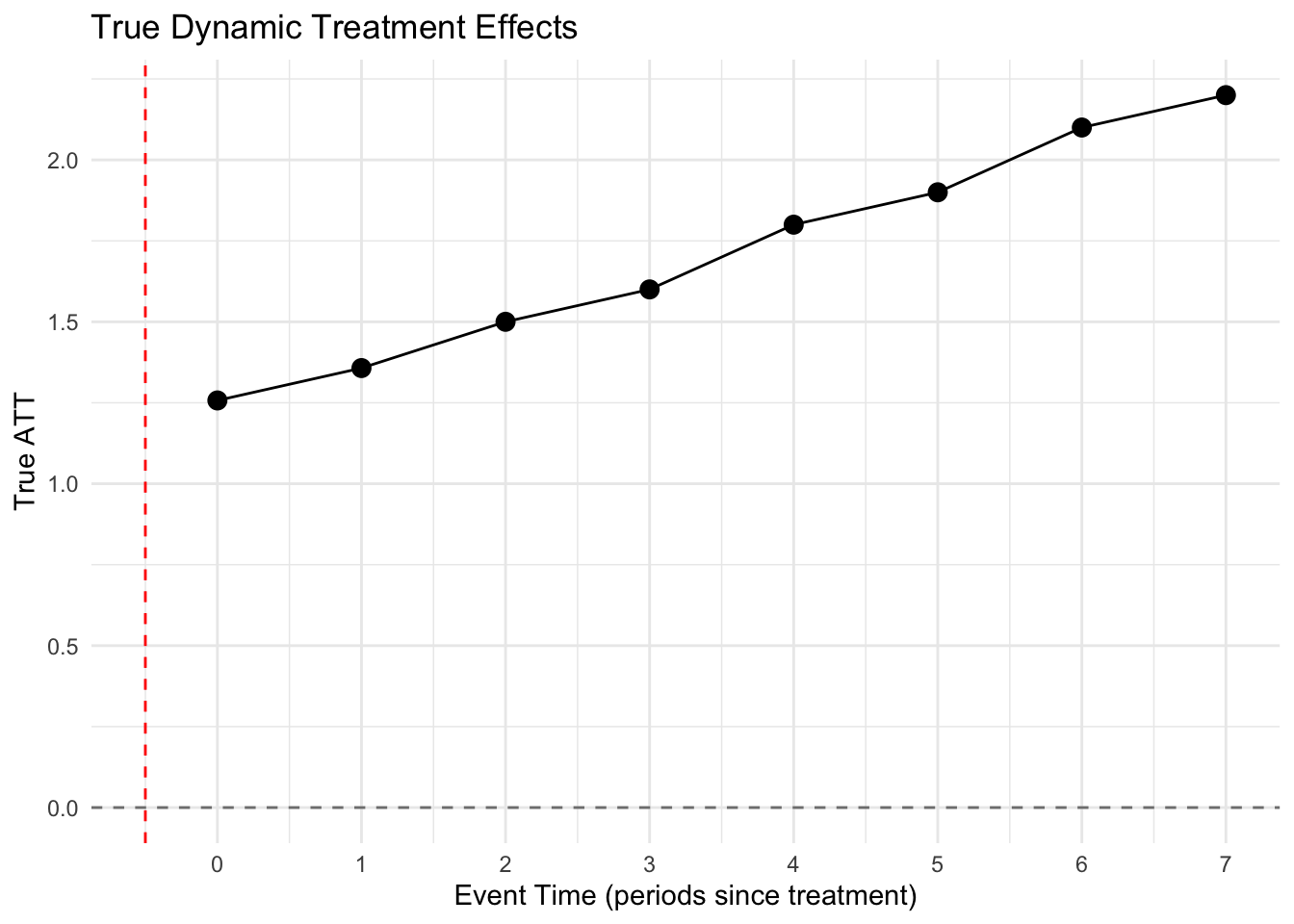
library(ggplot2)ggplot(dynamic_effects, aes(x = event_time, y = true_att)) +geom_point(size =3) +geom_line() +geom_hline(yintercept =0, linetype ="dashed", color ="gray50") +geom_vline(xintercept =-0.5, linetype ="dashed", color ="red") +labs(x ="Event Time (periods since treatment)",y ="True ATT",title ="True Dynamic Treatment Effects" ) +theme_minimal() +scale_x_continuous(breaks =-7:7)
True treatment effects by event time
3.4 Python Implementation
For Python packages, we’ll load the same data:
import numpy as npimport pandas as pd# Load the data generated by R for consistencydf = pd.read_csv("sim_data.csv")print(f"Loaded {len(df):,} observations")print(f"Units: {df['id'].nunique():,}")print(f"Periods: {df['year'].nunique()}")print(f"\nTreatment cohort distribution:")print(df.groupby('first_treat')['id'].nunique())