# Calculate true overall ATT for comparisontrue_overall_att <-mean(panel$tau_gt[panel$treated])cat("True overall ATT:", round(true_overall_att, 4), "\n")
True overall ATT: 1.5869
# Initialize results storageresults <-list()
4.1 1. Callaway & Sant’Anna (did package)
The did package implements the method from Callaway & Sant’Anna (2021), estimating group-time average treatment effects and aggregating them.
Method: Doubly-robust estimation combining outcome regression and propensity score weighting.
library(did)cat("Running did::att_gt()...\n")
Running did::att_gt()...
cat("This may take several minutes with 1M units.\n\n")
This may take several minutes with 1M units.
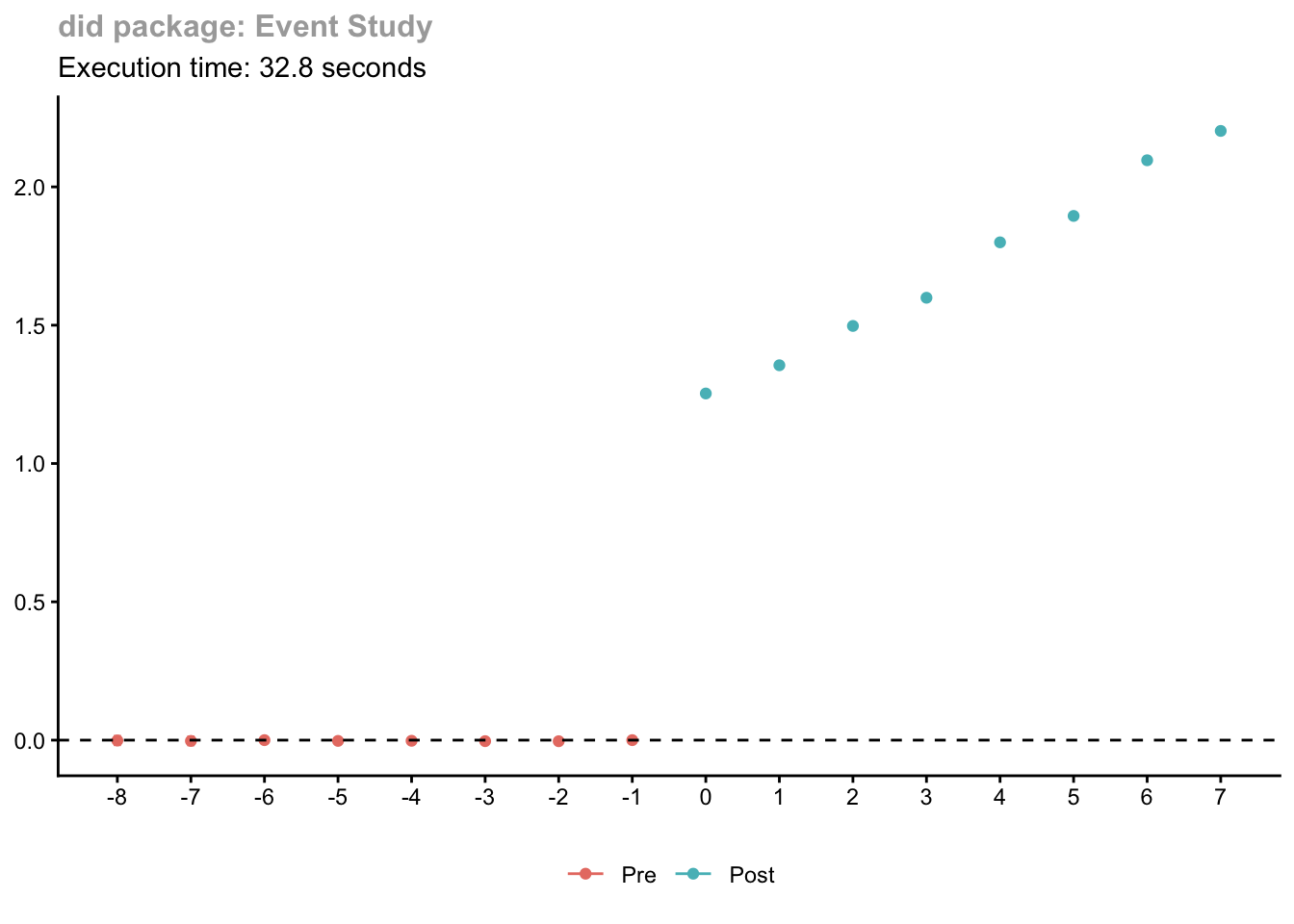
# Time the estimationstart_time <-Sys.time()# Estimate group-time ATTs# Using subset for large data (full data may require significant memory)out_cs <-att_gt(yname ="y",gname ="first_treat",idname ="id",tname ="year",data = panel,control_group ="nevertreated",est_method ="dr", # doubly robustbase_period ="universal")cs_time <-as.numeric(difftime(Sys.time(), start_time, units ="secs"))cat("\nExecution time:", round(cs_time, 2), "seconds\n")
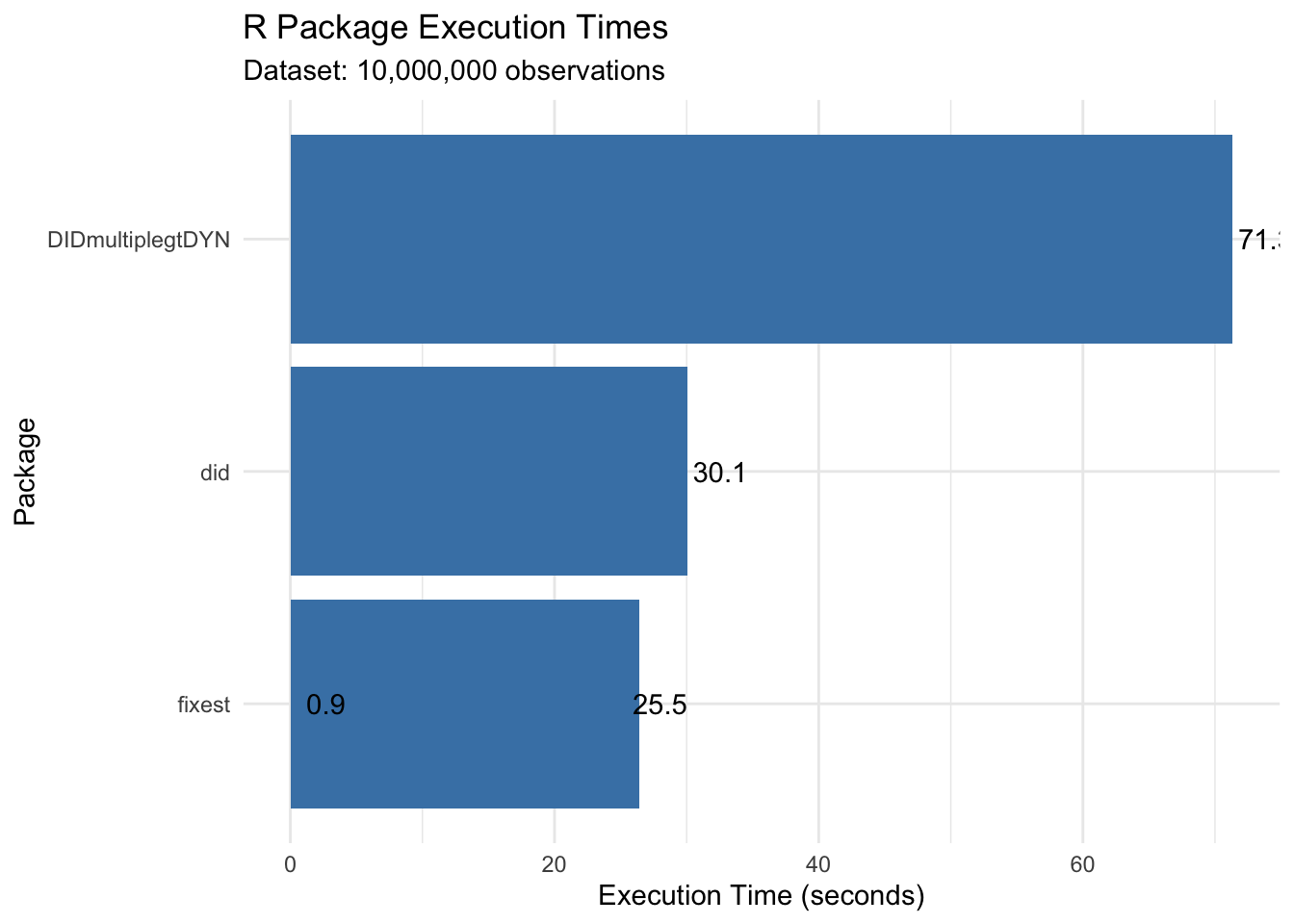
Execution time: 31.49 seconds
# Aggregate to overall ATTagg_cs <-aggte(out_cs, type ="simple")cat("\nOverall ATT estimate:", round(agg_cs$overall.att, 4), "\n")
4.2 2. de Chaisemartin & D’Haultfoeuille (DIDmultiplegtDYN)
The DIDmultiplegtDYN package implements the method from de Chaisemartin & D’Haultfoeuille, robust to heterogeneous treatment effects.
Method: Comparing switchers to non-switchers at each period.
# Check if package is availableif (requireNamespace("DIDmultiplegtDYN", quietly =TRUE)) {library(DIDmultiplegtDYN)library(dplyr) # for pipe operatorcat("Running DIDmultiplegtDYN::did_multiplegt_dyn()...\n")cat("This estimator can be slow with large datasets.\n\n")# Prepare data - DIDmultiplegtDYN needs treatment as binary panel_dcdh <- panel %>%mutate(D =as.integer(treated)) %>%select(id, year, y, D) start_time <-Sys.time()# Note: For very large datasets, this may require sampling# The package is computationally intensivetryCatch({ out_dcdh <-did_multiplegt_dyn(df = panel_dcdh,outcome ="y",group ="id",time ="year",treatment ="D",effects =5, # Number of event-study effectsplacebo =3, # Number of pre-treatment placeboscluster ="id",graph_off =TRUE ) dcdh_time <-as.numeric(difftime(Sys.time(), start_time, units ="secs"))cat("\nExecution time:", round(dcdh_time, 2), "seconds\n")print(summary(out_dcdh))# Extract ATT from results$ATE dcdh_att <- out_dcdh$results$ATEcat("\nAverage Total Effect (ATT):", round(dcdh_att, 4), "\n")cat("True ATT:", round(true_overall_att, 4), "\n") results$didmultiplegt <-list(package ="DIDmultiplegtDYN",method ="de Chaisemartin & D'Haultfoeuille",time = dcdh_time,att = dcdh_att,output = out_dcdh ) }, error =function(e) {cat("Error running DIDmultiplegtDYN:", e$message, "\n")cat("This package may have memory constraints with 1M observations.\n")cat("Consider using a subsample for this estimator.\n") results$didmultiplegt <<-list(package ="DIDmultiplegtDYN",method ="de Chaisemartin & D'Haultfoeuille",time =NA,error = e$message ) })} else {cat("Package DIDmultiplegtDYN not installed.\n")cat("Install with: install.packages('DIDmultiplegtDYN')\n") results$didmultiplegt <-list(package ="DIDmultiplegtDYN",method ="de Chaisemartin & D'Haultfoeuille",time =NA,error ="Package not installed" )}
Running DIDmultiplegtDYN::did_multiplegt_dyn()...
This estimator can be slow with large datasets.
Error running DIDmultiplegtDYN: vector memory limit of 36.0 Gb reached, see mem.maxVSize()
This package may have memory constraints with 1M observations.
Consider using a subsample for this estimator.
4.2.1 Alternative: Using a subsample
Due to computational constraints, we may need to use a subsample:
if (requireNamespace("DIDmultiplegtDYN", quietly =TRUE) && (is.null(results$didmultiplegt$time) ||is.na(results$didmultiplegt$time))) {library(DIDmultiplegtDYN)library(dplyr) # for pipe operatorcat("Running DIDmultiplegtDYN on 10% subsample...\n")# Sample 10% of unitsset.seed(123) sample_ids <-sample(unique(panel$id), size =100000) panel_sample <- panel %>%filter(id %in% sample_ids) %>%mutate(D =as.integer(treated)) %>%select(id, year, y, D)cat("Subsample size:", format(nrow(panel_sample), big.mark =","), "\n\n") start_time <-Sys.time()tryCatch({ out_dcdh_sample <-did_multiplegt_dyn(df = panel_sample,outcome ="y",group ="id",time ="year",treatment ="D",effects =5,placebo =3,cluster ="id",graph_off =TRUE ) dcdh_time_sample <-as.numeric(difftime(Sys.time(), start_time, units ="secs"))cat("\nExecution time (10% sample):", round(dcdh_time_sample, 2), "seconds\n")cat("Estimated full data time:", round(dcdh_time_sample *10, 2), "seconds\n")print(summary(out_dcdh_sample))# Extract ATT from results$ATE dcdh_att_sample <- out_dcdh_sample$results$ATEcat("\nAverage Total Effect (ATT):", round(dcdh_att_sample, 4), "\n")cat("True ATT:", round(true_overall_att, 4), "\n") results$didmultiplegt_sample <-list(package ="DIDmultiplegtDYN",method ="de Chaisemartin & D'Haultfoeuille (10% sample)",time = dcdh_time_sample,att = dcdh_att_sample,estimated_full_time = dcdh_time_sample *10,output = out_dcdh_sample ) }, error =function(e) {cat("Error:", e$message, "\n") })}
Running DIDmultiplegtDYN on 10% subsample...
Subsample size: 1,000,000
Execution time (10% sample): 76.09 seconds
Estimated full data time: 760.9 seconds
----------------------------------------------------------------------
Estimation of treatment effects: Event-study effects
----------------------------------------------------------------------
Estimate SE LB CI UB CI N Switchers
Effect_1 1.23956 0.00624 1.22734 1.25179 279,385 70,318
Effect_2 1.35506 0.00621 1.34288 1.36723 279,385 70,318
Effect_3 1.49808 0.00708 1.48420 1.51196 189,344 60,368
Effect_4 1.59630 0.00709 1.58241 1.61020 189,344 60,368
Effect_5 1.79333 0.00890 1.77589 1.81077 109,652 40,338
Test of joint nullity of the effects : p-value = 0.0000
----------------------------------------------------------------------
Average cumulative (total) effect per treatment unit
----------------------------------------------------------------------
Estimate SE LB CI UB CI N Switchers
1.46362 0.00528 1.45327 1.47398 719,844 301,710
Average number of time periods over which a treatment effect is accumulated: 2.7683
----------------------------------------------------------------------
Testing the parallel trends and no anticipation assumptions
----------------------------------------------------------------------
Estimate SE LB CI UB CI N Switchers
Placebo_1 -0.00871 0.00624 -0.02094 0.00353 279,385 70,318
Placebo_2 -0.01505 0.00749 -0.02974 -0.00037 179,385 50,409
Placebo_3 -0.00406 0.00887 -0.02144 0.01333 109,773 40,459
Test of joint nullity of the placebos : p-value = 0.2133
The development of this package was funded by the European Union.
ERC REALLYCREDIBLE - GA N. 101043899
NULL
Average Total Effect (ATT): 1.4636 0.0053 1.4533 1.474 719844 301710 719844 301710
True ATT: 1.5869
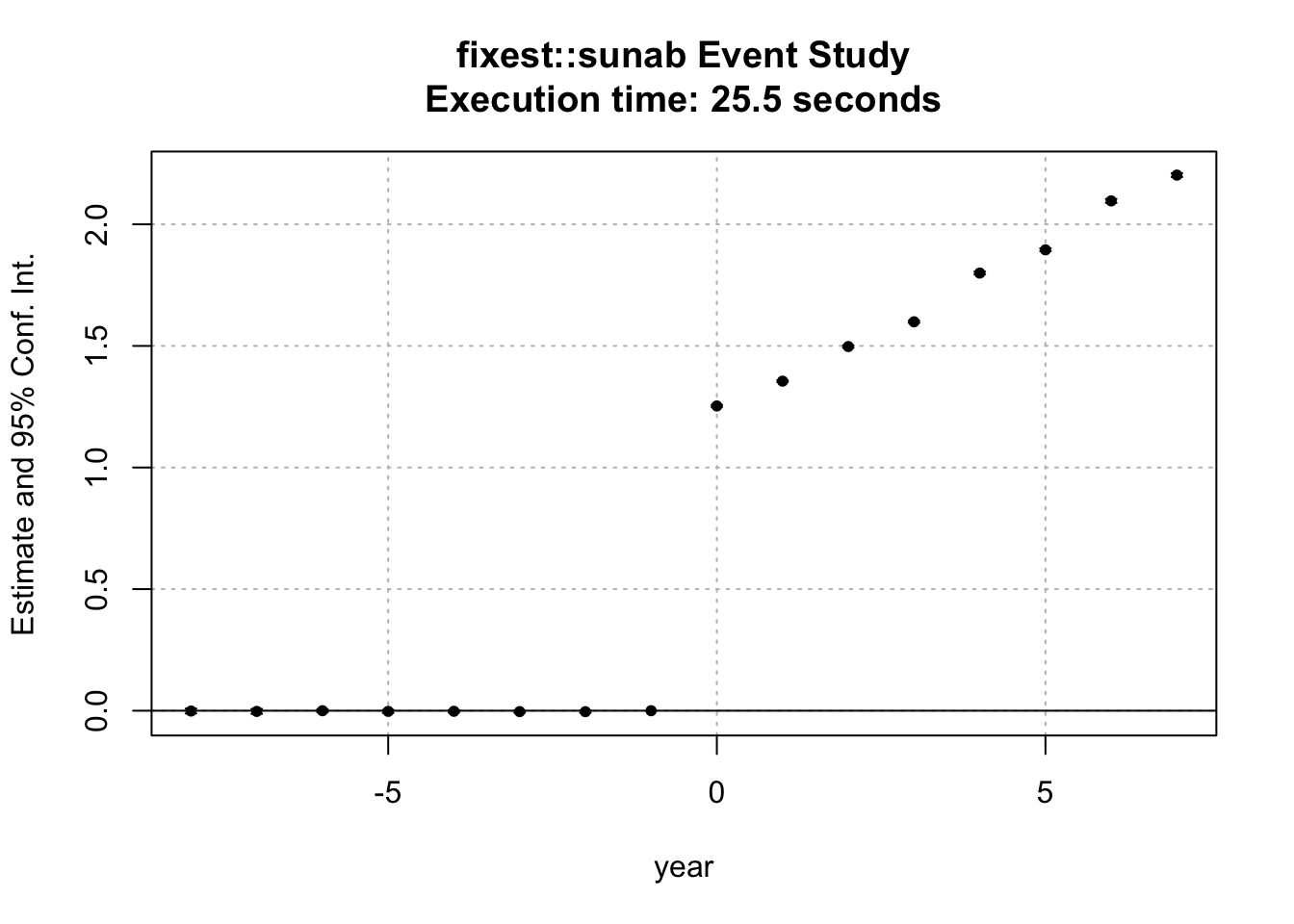
4.3 3. Sun & Abraham (fixest::sunab)
The fixest package provides the interaction-weighted estimator from Sun & Abraham (2021) through the sunab() function.
Method: Cohort-specific coefficients with clean controls.
library(fixest)cat("Running fixest::feols() with sunab()...\n\n")
Running fixest::feols() with sunab()...
# Create cohort variable for sunabpanel_sa <- panel %>%mutate(cohort =ifelse(first_treat ==0, Inf, first_treat), # Never-treated = Infrel_time =ifelse(first_treat ==0, -1000, year - first_treat) # Relative time )start_time <-Sys.time()# Sun & Abraham estimation using sunabout_sa <-feols( y ~sunab(cohort, year) | id + year,data = panel_sa,cluster =~id)sa_time <-as.numeric(difftime(Sys.time(), start_time, units ="secs"))cat("Execution time:", round(sa_time, 2), "seconds\n\n")